its time to learn cuda
my notes on nvidia ampere (ga104) gpu architecture----------------------------------------------------
----------------------------------------------------
device: threads > blocks > grid
data: tile
all threads within a single block have shared mem, but threads in different blocks can only share via global mem
first version of matx with tile size 16 ended up doing better than both 32 and 8
max shared memory per block: 48 KBat 4KB per 16x16 that leaves plenty of room for double-buffered tiling. 32x32 would use up too much shared mem
gpt says " Aim to keep all SMs busy by launching enough blocks to maximize occupancy. For example, launching around 46 * 2 = 92 or more blocks would help keep all SMs engaged."
blocks should be a multiple of warp size(32) that fits in max threads(1024). so something like 256 or 512
gpt says " Coalescing Memory Accesses: Design your memory access patterns to be aligned to 32-thread warps to improve memory coalescing, meaning that threads in a warp access contiguous memory addresses. This reduces the number of memory transactions and increases bandwidth utilization."
again, gpt says " Each SM can handle a maximum of 16 resident blocks at once. Therefore, try to design your grid and block configuration to stay below this limit. If your kernel uses very few registers and shared memory, aim for higher occupancy by launching multiple blocks per SM to leverage all available SMs."
need to read up on SM, registers, coalescing memory access
----------------------------------------------------
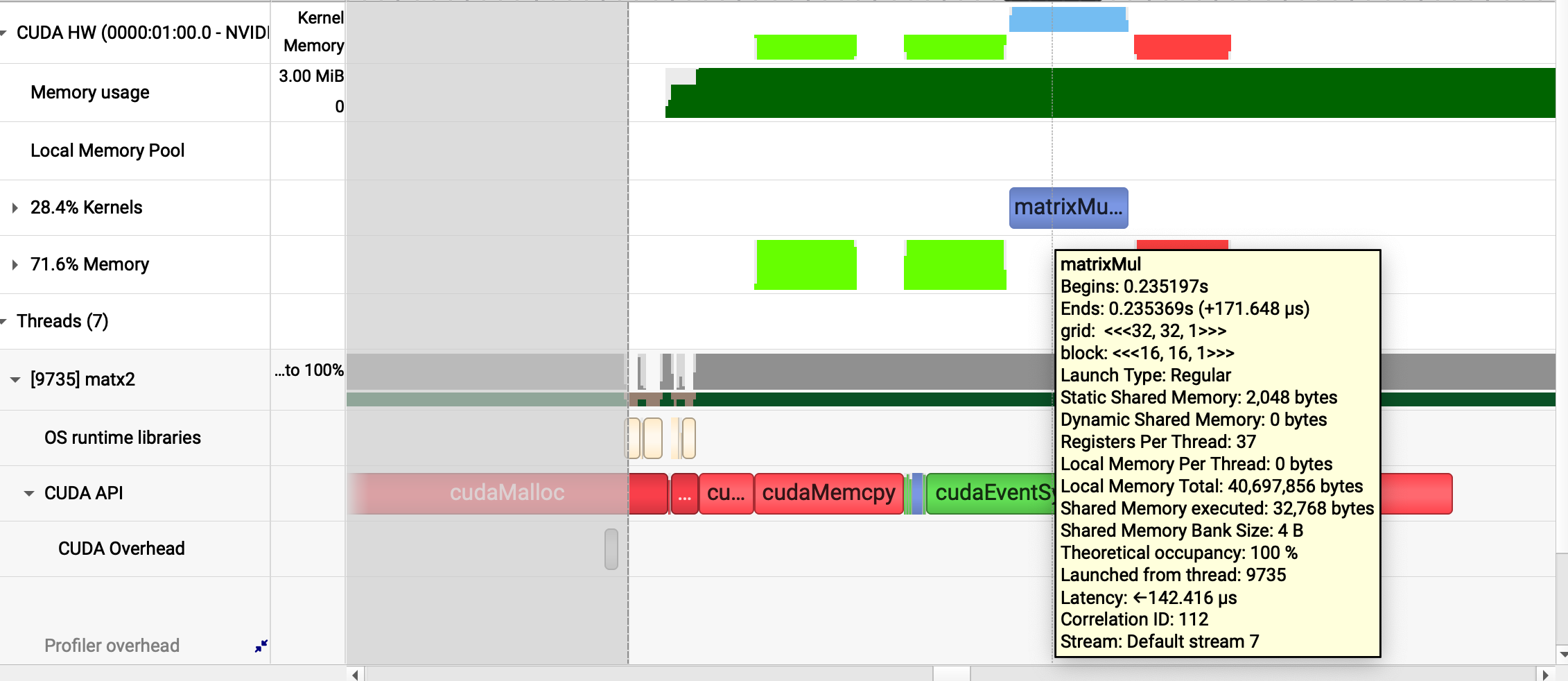
total thing says like 200ms
but actual matxMul is only 142us
call to cudaMalloc alone is 75ms
this cant be the right way to do this stuff, 99% of time spent not actually doing the thing?
----------------------------------------------------
----------------------------------------------------
directory