--------------------------------
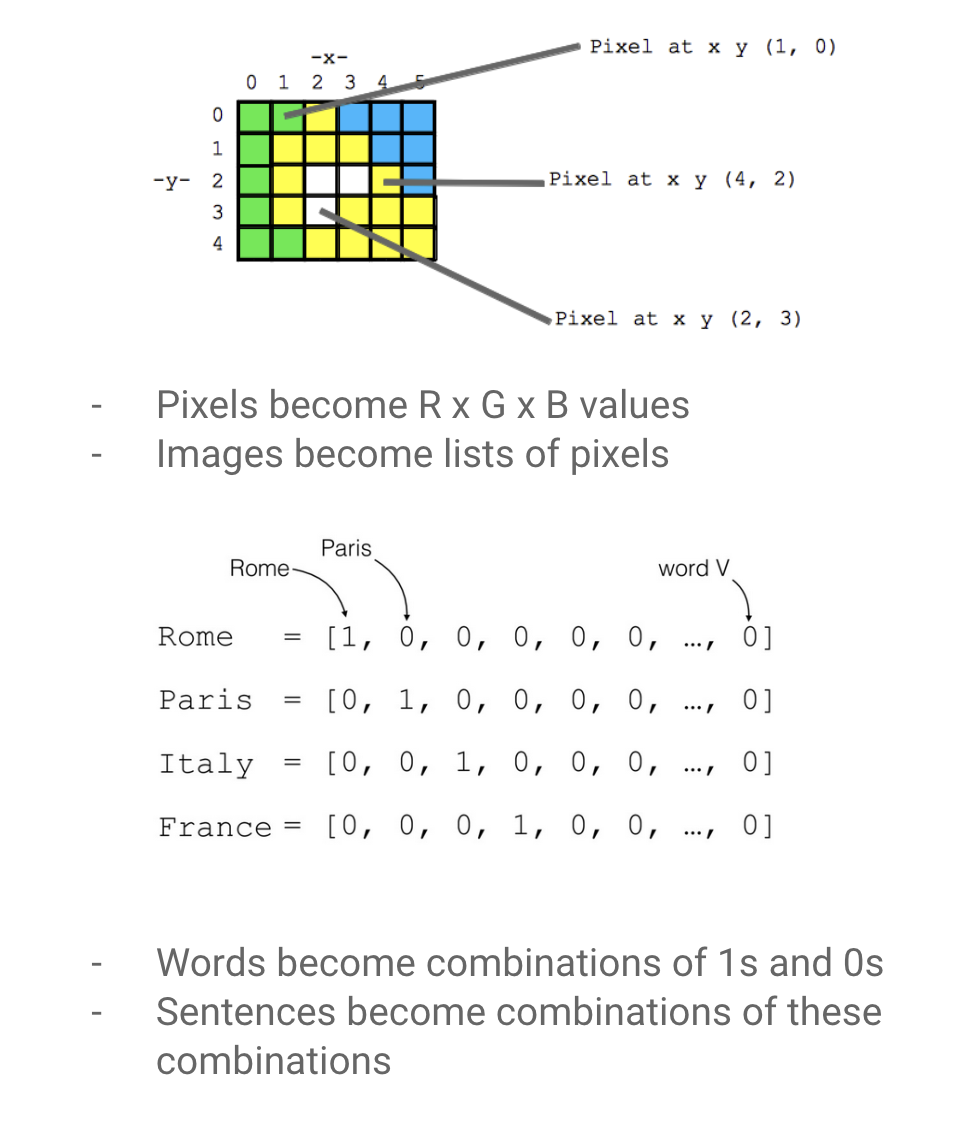
humans have learned and continue to learn ways of representing things we observe in the world, as sets of numerical values
--------------------------------
2024:
Out:one hot encoding
In:Large embedding models
--------------------------------
--------------------------------
recommendation systems are often an undervalued application of ml but vital to some of the biggest companies you know netflix, spotify, google, amazon
a rather simple yet effective recoomendation strategy is to use the embedding of users past vists, and show them similar content based on the cosine similarity of the embeddings
similarities between users and items simultaneously to provide recommendations
collaborative filtering models can recommend an item to user A based on the interests of a similar user B
the hard part is finding a way to represent user A and B in ways that allow for measuring the similarities between users, often not being explicit
--------------------------------
given your content now represented as vectors, this enables us to do search over content during conversational settings to incorporate additional context
notice a trend yet? the same vectors can be used for content recommendations, site search, retrieval augmented generation, etc
--------------------------------
just like all ml systems, downstream performance is still dependent on the quality of your data
in this case, some thought should be given to what you are embedding on both ends of the comparison
either preprocessing or post processing can be used to handle imperfect data
your data in this case being both the stored content vectors as well as the vectorized user query
preprocess your data by cleaning or formatting
also developing a good chunking strategy to incorporate as much context in chunks while keeping some token limit
formatting is your friend ex. markdown, html
ex 1.
ex 2.
if i gave you some 'context' but it was just the header of some seciton of content, how useful would that be? if i gave you some random paragraph without knowing the section it came from, the might be useful
but if i gave you a paragraph and told you what section it came from, much more helpful in terms of context
you cant expect users to provide perfect search queries, but you can absolutely alter their query to something that will return better results
"You are a rewriting assistant tasked with taking some user query and their current conversation, and returning an optimized search query that will be used to retrieve useful information relevant to their query"
embedding models are trained on large datasets encouraging generalization of similarity no matter the domain
generalization also leads to non-optimal ranks while still being close
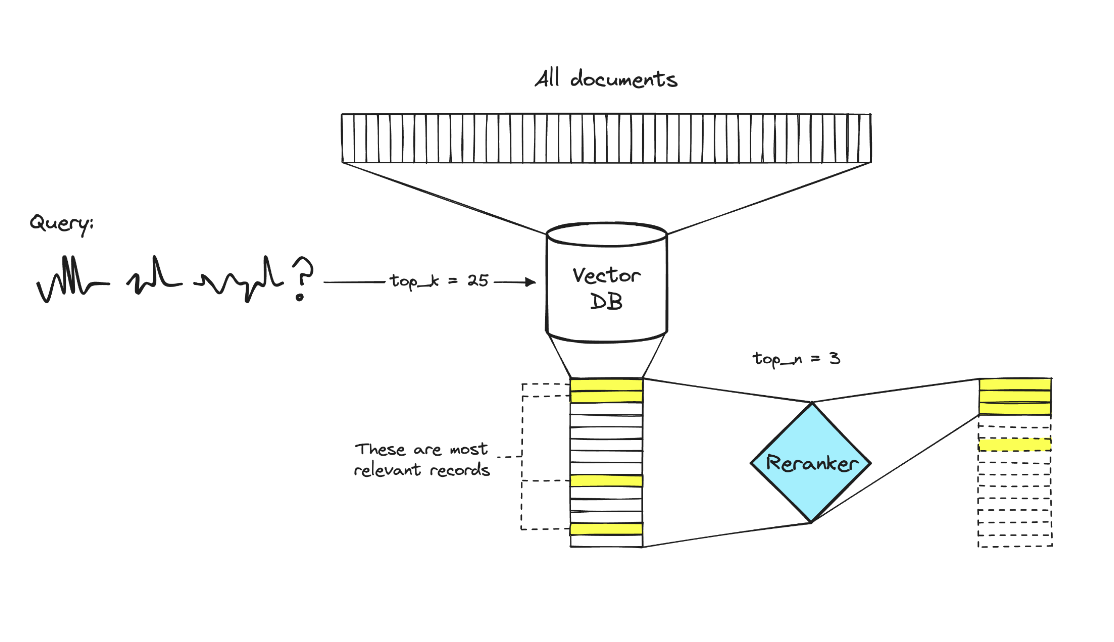
it is very likely the 2 best documents for your search are within the top 10-25 but may not actually be the 1 and 2 ranked items from initial search
to further improve, incorporate a reranking model that considers something like 25 candidate documents from initial search, and reranks those to determine top 2
use some fast generalized model to search 10000s of documents and narrow down to 25 candidate documents, then use a more performant but slower model on those 25 to get final 2-5 items
--------------------------------
directory--------------------------------