AWS has built 2 different versions of specialized ML chips or Accelerators, for training and inference
here i will cover the neuron, tranium, and inferentia architectures. along with outlining the differences between tranium and inferentia.
one of my main motivations to dive deeper into the inferentia and tranium architectures was to better understand the technical differences, leading to one being better for inference and the other better for training.
at a glance they seem awfully similar given they are both powered by some number of neuroncore-v1/2/3 chips. the most obvious place of difference is in their memory. trainium uses HBR while inferentia uses DDR.
to better understand the reasoning behind the difference in memory choice, lets recap latency vs bandwith. latency:the delay before a transfer of data begins following an instruction for its transfer. bandwith the maximum possible amount of data transfer between two points of a network in a specific time
relating these definitions back to inference and training, latency is a priority for inference because we are typically producing a single output where the speed of getting that output is important. while we typically dont need the output of training immediately, but are typically trying to process a large amount of data together, hence the need for bandwith.
so going back, trainium uses HBM, which literally stands for High Bandwith Memory, because training runs prioritize processing tons of examples together. while inferentia uses DDR, a more typical memory, because the cost-benefit is much lesser given latency is the priority in inference scenarios.
cost is also a noticable difference between these instances. with inferentia being considerably cheaper. again this can be related back to the fundamental differences between the focuses for each instance. when it comes to optimizing for training, your focus is on a single cluster and a known size of large data. but when building for inference your optimizations also include scalability for dynamic volumes of usage, handled by spinning up instances at any moment to help with increases in traffic.
-------------------------------------
-------------------------------------
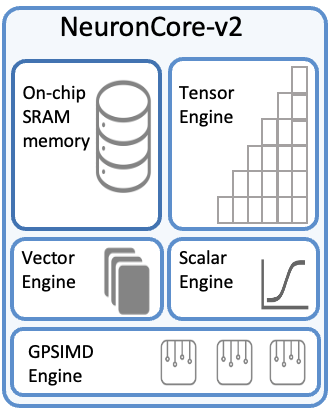
4 main engines, tensor, vector, scalar, and GPSIMD
each nc-v3 has 28mb of on-chip software-managed SRAM to maximize data locality and optimize data prefetch
tensor engines highly optimized for GEMM, CONV, and transpose. supporting mixed-precision computation.
tensor cores in v3 deliver 79 fp16 TFLOPS of tensor operations
also delivers 316 fp16 TFLOPS with Structured Sparsity, useful when on input tensor in matmul has M:N sparsity pattern, where only M elements out of every N contiguous elements are non-zero
vector engine optimized for vector comp in which ever element of the output is dependent on multple input elements. like layernorm or pooling
scalar enginer optimized for scalar operations, where every element of the output is dependent on one element of the input
-------------------------------------
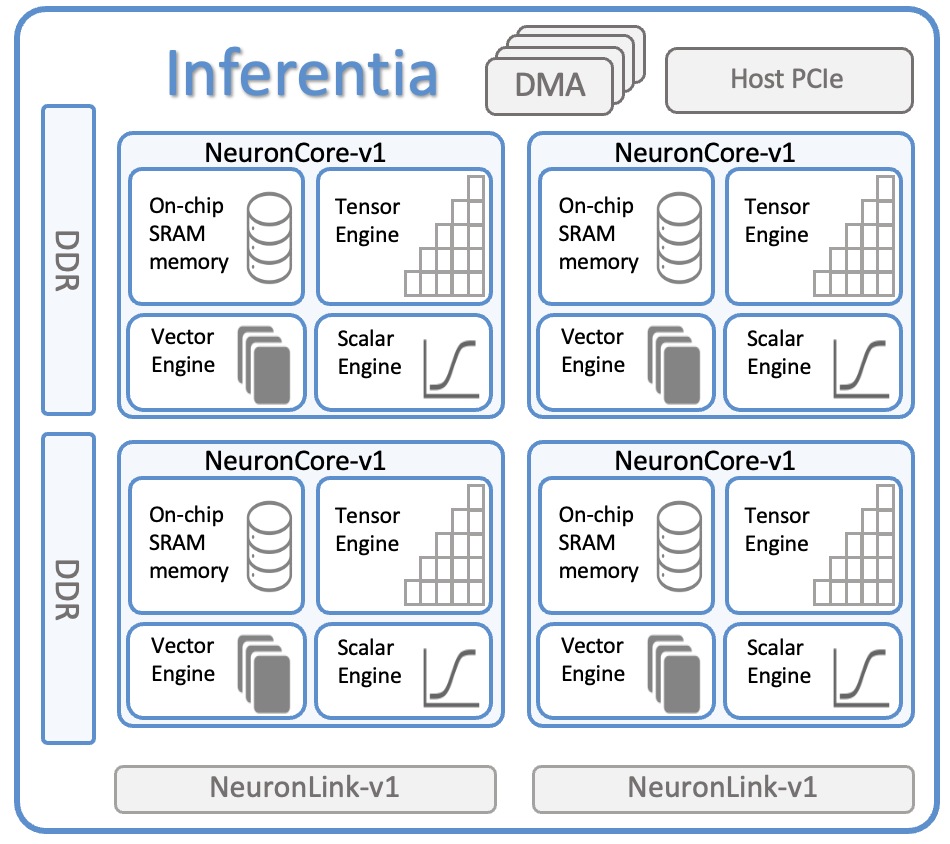
each inf1 instance has x16 inferentia chips, each with x4 neuroncore-v1 cores
128 int8 TOPS and 64 fp16 TFLOPS
8gb device DRAM/DDR4 for storing parameters and intermediate state
each inf2 has x12 inferentia2 chips
190 TFLOPS of fp16
32gb HBM mem, which is x4 inferentia1
inf1.24xlarge is $4.72/hr
inf2.48xlarge is $12.98/hr
<-------------------------------------
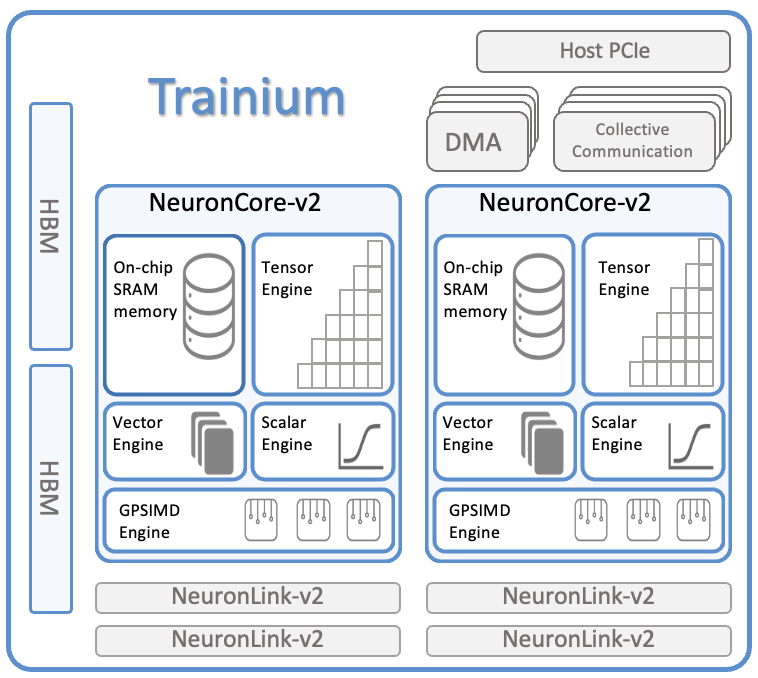
each trn1 has x16 tranium chips, each with x2 neuroncore-v2 cores
each trn2 ultraserver instance has x64 tranium2 chips aka x4 trn2
trn2 does 20.8 PFLOPS of fp8, so ultraserver does 83.2 PFLOPS
trn2 has 1.5TB of HBM3
trn1.32xlarge is $15.50/hr on demand
trn2.48xlarge is $44.701
-------------------------------------
compiling and deploying BERT on trn1/trn2-------------------------------------
directory-------------------------------------