llms, training, inference, 2025
some understanding of attention and modern transformers is assumed.
kv cache attention variations
kv cache enables resuse of the key and value matrices from previous tokens.
due to the nature of autoregressive models, the nth token output requires
computing all 0 to n-1 tokens as well. luckily we can just cache the outputs
of those computations and reuse them to compute n. the drawback is that kv
matrices are not necessarily comprised of small vectors, but rather pretty
large and especially so in cases of long context, think 100k tokens up to 1m
tokens.
due to the memory requirements of large kv stores, it is a major bottleneck
and a constant focus point for innovating solutions. a few being mqa, gqa, and
mla. in addition to other efforts to quantize kv caches.
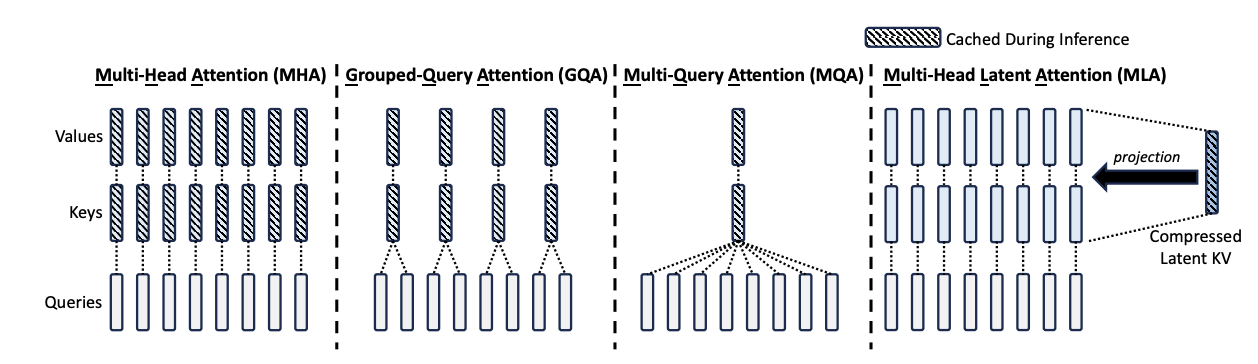
to summarize the figure above:
- mha uses 1:1 kv to q, resulting in most kv requirements
- mqa use single kv for all q, least mem reqs but perf hurt
-
gqa uses single kv for groups of q, middle mem reqs, minimal perf loss
-
mla uses representation of kv instead of actual kv, more mem reqs than mqa
but better perf than gqa
post training
pre training is the step in llms that give the model huge amounts of
unstructured data to teach it general text and world knowledge, while post
training is what gives models their assistant like characteristics and make
them useful to users.
post training is also the primary concern for companies, given most foundation
models and pretraining are the work of labs and teams not necessarily focused
on a specific user base. llama and qwen are the most popular foundations to
build from.
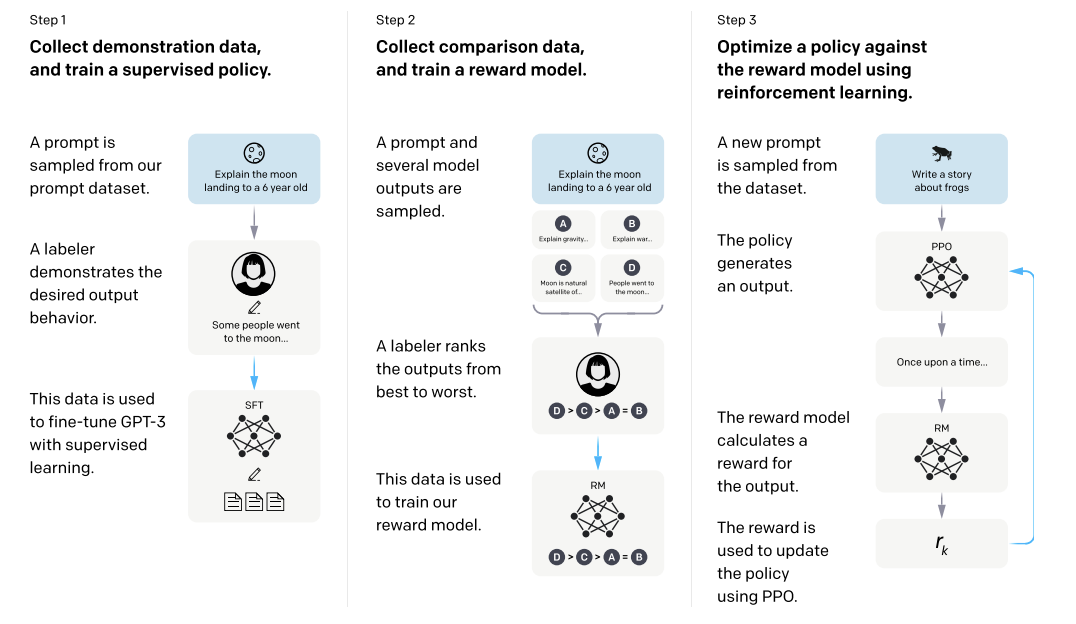
-
openai researchers published a notable paper in 2022 that discussed how they
conduct reinforcement learning with human feedback through stages from:
-
using SFT to finetune a base model on human annotated candidate
generations, results in instruct model
-
sample from this model and have human labeler rank candidate ouputs in
order of preference. these examples are used to train a reward model.
-
finally, PPO is conducted with a base model/policy that generates
outputs, the reward model from step 2 calculates a reward for the
output, and the reward is used to update the policy
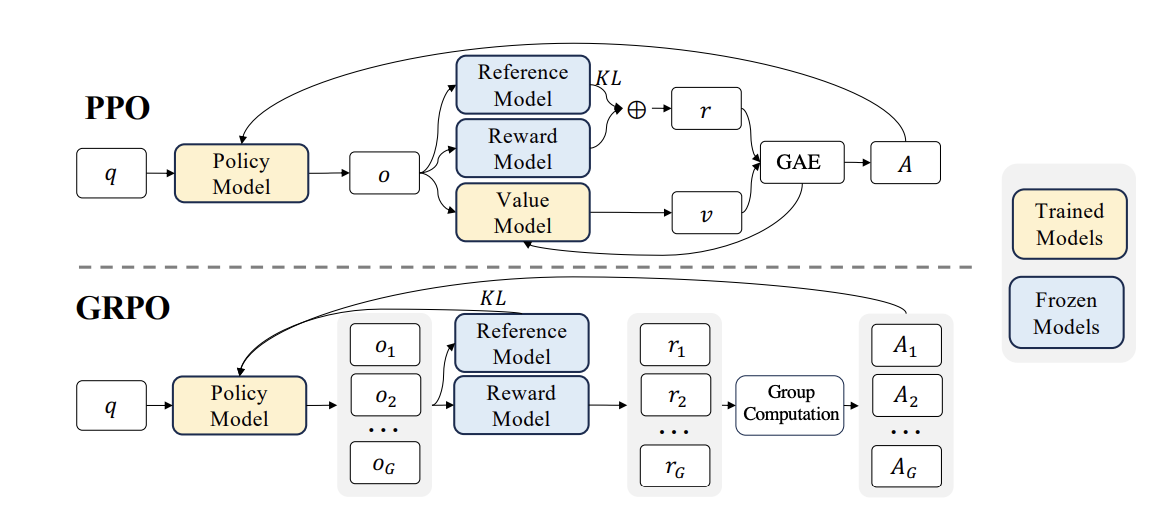
to summarize the figure above:
-
grpo was recently introduced by deepseek as an updated policy optimization
method from the prior ppo. ppo can be incur large resource requirements due
to maintaining multiple similar sized models throughout training. where grpo
does without the value model and instead uses the average of the group as
the baseline. grpo also plays well into the nature of po in which we compare
multiple generation examples with the goal of getting closer to a model that
produces the most desired generation.
hardware aware algorithms and techniques
positional
sequence length
directory